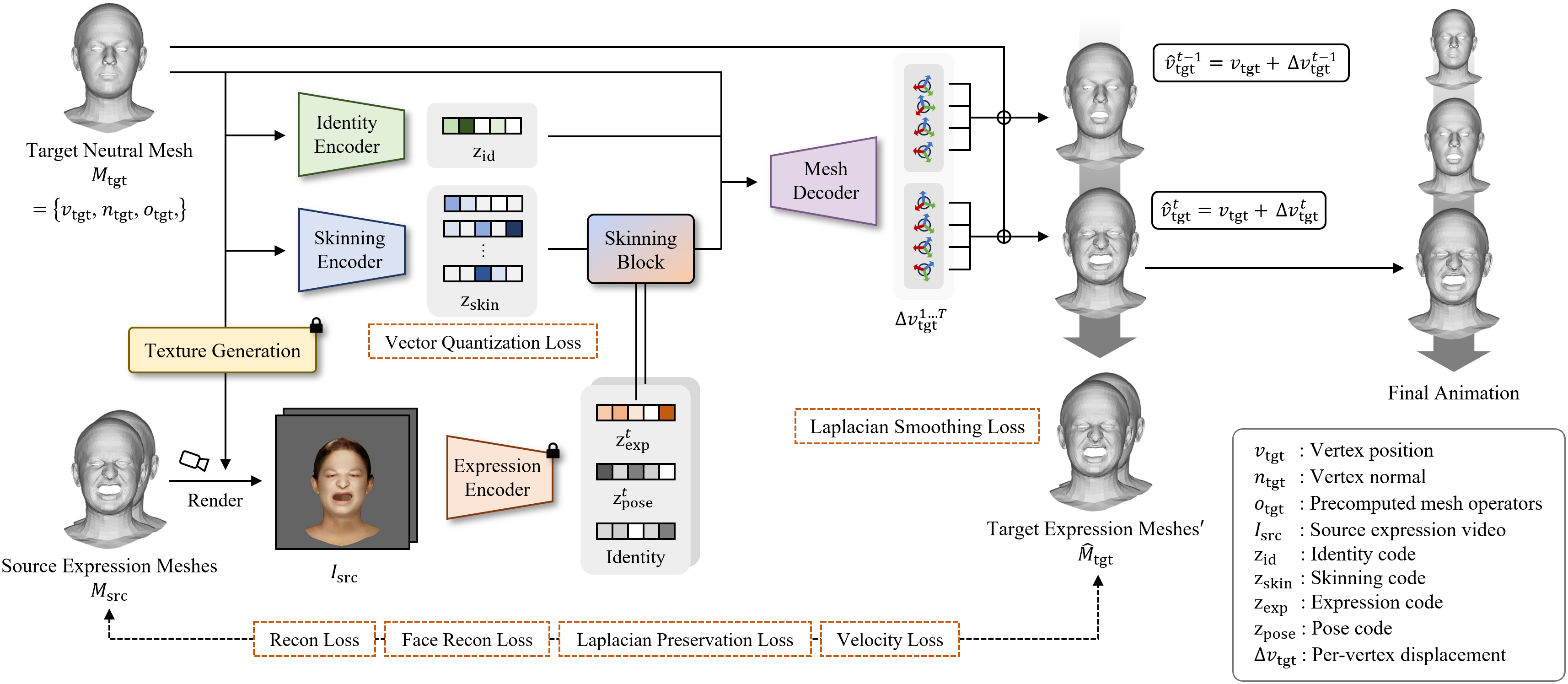
We present Anymate, an end-to-end method for capturing and retargeting facial animation from RGB videos to 3D face meshes with various shapes and mesh structures. Our approach tackles the challenge of animating arbitrary 3D faces from in-the-wild video without relying on shared mesh structures or manual correspondences Most existing methods address facial expression capture and retargeting as separate problems, necessitating an additional mechanism to bridge the two tasks. To address this gap, we introduce Anymate, a novel method that animates arbitrary target meshes using source performance videos. Anymate disentangles expression, identity, and skinning features through dedicated encoders and predicts per-vertex deformations using a mesh-agnostic decoder. Temporal coherency is maintained by aggregating expression features across consecutive frames using a temporally aware decoder. In addition, we employ a Laplacian preservation loss to encourage smooth and natural surface deformations, and a Laplacian smoothing loss to suppress local artifacts by promoting surface regularity. Despite being trained on a limited set of templates, Anymate can be generalized to unseen characters at inference time, producing animations that accurately reflect the source performance while preserving the identity of the target mesh. Quantitative and qualitative evaluations including a user study demonstrate that Anymate outperforms state-of-the-art approaches.